class Employee:
def __init__(self, name, position=None, pay=0):
self.name = name
self.position = position
self.pay = pay
def _repr_html_(self):
html_str = """
이름: {} <br/>
직급: {} <br/>
연봉: {} <br/>
""".format(self.name, self.position, self.pay)
return html_str
def giveraise(self,pct):
self.pay = self.pay * (1+pct)
클래스 공부 6단계
- 상속
인사관리 예제
- 아래와 같은 클래스를 만들자. - 이름, 직급, 연봉에 대한 정보가 있다. - 연봉을 올려주는 메소드가 존재
- 확인
iu = Employee('iu', position='staff', pay=5000)
hynn = Employee('hynn', position='staff', pay=4000)
hd = Employee('hodonh', position='mgr', pay=8000)iu
이름: iu
직급: staff
연봉: 5000
직급: staff
연봉: 5000
hynn
이름: hynn
직급: staff
연봉: 4000
직급: staff
연봉: 4000
hd
이름: hodonh
직급: mgr
연봉: 8000
직급: mgr
연봉: 8000
iu.giveraise(0.1)iu
이름: iu
직급: staff
연봉: 5500.0
직급: staff
연봉: 5500.0
hynn.giveraise(0.2)hynn
이름: hynn
직급: staff
연봉: 4800.0
직급: staff
연봉: 4800.0
- 회사의 모든 직원의 연봉을 10%씩 올려보자.
iu = Employee('iu', position='staff', pay=5000)
hynn = Employee('hynn', position='staff', pay=4000)
hd = Employee('hodonh', position='mgr', pay=8000)for i in [iu, hynn, hd]:
print(i.name)iu
hynn
hodonhfor i in [iu, hynn, hd]:
i.giveraise(0.1) # 일괄적으로 상승iu
이름: iu
직급: staff
연봉: 5500.0
직급: staff
연봉: 5500.0
hynn
이름: hynn
직급: staff
연봉: 4400.0
직급: staff
연봉: 4400.0
hd
이름: hodonh
직급: mgr
연봉: 8800.0
직급: mgr
연봉: 8800.0
- 매니저 직급은 일반직원들의 상승분에서 5%의 보너스가 추가되어 상승한다고 가정
- 모든회사 직원들의 연봉을 10% 상승
(구현1) if문을 통한
iu = Employee('iu', position='staff', pay=5000)
hynn = Employee('hynn', position='staff', pay=4000)
hd = Employee('hodonh', position='mgr', pay=8000)for i in [iu,hynn,hd]:
if i.position == 'mgr':
i.giveraise(0.1 + 0.05)
else:
i.giveraise(0.1)iu
이름: iu
직급: staff
연봉: 5500.0
직급: staff
연봉: 5500.0
hynn
이름: hynn
직급: staff
연봉: 4400.0
직급: staff
연봉: 4400.0
hd
이름: hodonh
직급: mgr
연봉: 9200.0
직급: mgr
연봉: 9200.0
(구현2) 새로운 클래스를 만들자
class Manager:
def __init__(self, name, position=None, pay=0):
self.name = name
self.position = position
self.pay = pay
def _repr_html_(self):
html_str = """
이름: {} <br/>
직급: {} <br/>
연봉: {} <br/>
""".format(self.name, self.position, self.pay)
return html_str
def giveraise(self,pct):
self.pay = self.pay * (1+pct+0.05)
iu = Employee('iu', position='staff', pay=5000)
hynn = Employee('hynn', position='staff', pay=4000)
hd = Manager('hodonh', position='mgr', pay=8000)for i in [iu,hynn,hd]:
i.giveraise(0.1)iu
이름: iu
직급: staff
연봉: 5500.0
직급: staff
연봉: 5500.0
hynn
이름: hynn
직급: staff
연봉: 4400.0
직급: staff
연봉: 4400.0
hd
이름: hodonh
직급: mgr
연봉: 9200.000000000002
직급: mgr
연봉: 9200.000000000002
- 구현3: 이미 만들어진 클래스에서
class Manager(Employee):
# 나머지 기타 함수내용은 Emplyee 클래스와 같음걸 표현하려면 위 가로에 Employee를 작성한다.
def giveraise(self,pct):
self.pay = self.pay * (1+pct+0.05)
hd=Manager('hodong',pay=8000)
hd # 명시하지 않았는데 상속됨
이름: hodong
직급: None
연봉: 8000
직급: None
연봉: 8000
iu = Employee('iu', position='staff', pay=5000)
hynn = Employee('hynn', position='staff', pay=4000)
hd = Manager('hodonh', position='mgr', pay=8000)for i in [iu,hynn,hd]:
i.giveraise(0.1)iu
이름: iu
직급: staff
연봉: 5500.0
직급: staff
연봉: 5500.0
hynn
이름: hynn
직급: staff
연봉: 4400.0
직급: staff
연봉: 4400.0
hd
이름: hodonh
직급: mgr
연봉: 9200.000000000002
직급: mgr
연봉: 9200.000000000002
- 요약: 이미 만들어진 클래스에서 대부분의 기능은 그대로 쓰지만 일부기능만 변경 혹은 추가하고 싶다면 클래스를 상속하면 된다!
리스트의 상속
- 내가 만든 클래스를 계속 상속하는 경우
- list 와 비슷한데 멤버들의 빈도가 계산되는 메소드를 포함하는 새로운 나만의 list를 만들자
lst = ['a','b','a','c','b','a','d']
lst['a', 'b', 'a', 'c', 'b', 'a', 'd']- 아래와 같은 딕셔너리를 만들고 싶다.
freq = {'a':3, 'b':2, 'c':1, 'd':1} # 갯수
freq{'a': 3, 'b': 2, 'c': 1, 'd': 1}- lst.frequency()를 입력하면 위의 기능이 수행되도록 변형된 list를 쓰고 싶다.
- 구현
(시도1) 절반 성공
freq = {'a':0, 'b':0, 'c':0, 'd':0} # 일단 다 0이라 생각하고 코드 짜기
freq{'a': 0, 'b': 0, 'c': 0, 'd': 0}for item in lst:
print(item)a
b
a
c
b
a
dfor item in lst:
print(freq[item])0
0
0
0
0
0
0for item in lst:
freq[item] = freq[item] + 1freq{'a': 3, 'b': 2, 'c': 1, 'd': 1}반쯤 성공.. 리스트가 a,b,c,d 라는걸 알고 있어야 함
(시도2) 실패
lst['a', 'b', 'a', 'c', 'b', 'a', 'd']freq = dict()
freq{}for item in lst:
freq[item] = freq[item] + 1KeyError: 'a'freq['a'] # 매칭되는게 없다!KeyError: 'a'에러이유? freq['a'] 를 호출할 수 없다 -> freq.get('a',0)을 이용
freq.get('a') # 4주차 3월 23일 복습 get메소드를 사용하면 없어도 에러를 표시하지 않음freq.get?Signature: freq.get(key, default=None, /) Docstring: Return the value for key if key is in the dictionary, else default. Type: builtin_function_or_method
- key에 대응하는 값이 있으면 그 값을 리턴하고 없으면 default를 리턴
freq.get('a',0) # a값 없으면 0으로 리턴0(시도3)
lst['a', 'b', 'a', 'c', 'b', 'a', 'd']freq = dict()
freq{}for item in lst:
freq[item] = freq.get(item,0) + 1freq{'a': 3, 'b': 2, 'c': 1, 'd': 1}- 이것을 내가 정의하는 새로운 list의 메소드로 넣고 싶다.
class L(list): # L 이라는 클래스에 list에 있는 모든걸 상속받겠다.
passa=[1,2,3]
a[1, 2, 3]a?Type: list String form: [1, 2, 3] Length: 3 Docstring: Built-in mutable sequence. If no argument is given, the constructor creates a new empty list. The argument must be an iterable if specified.
class L(list):
def frequency(self):
freq = dict()
for item in self:
freq[item] = freq.get(item,0) + 1
return freqlst = L([1,1,1,2,2,3])lst? SyntaxError: invalid syntax (<ipython-input-96-8d8983ef4faf>, line 1) # 리스트 같아 보이지만 타입이 L! 내가 설정한 클래스lst #원래 list에 있는 repr 기능을 상속받아서 이루어지는 결과[1, 1, 1, 2, 2, 3]_lst = L([4,5,6])
_lst + _lst # L자로형끼리 덧셈[4, 5, 6, 4, 5, 6]lst + [4,5,6] # l자료형과 list 자료형의 덧셈도 가능[1, 1, 1, 2, 2, 3, 10, 10, 4, 5, 6]- L자료형의 덧셈은 list의 덧셈과 완전히 같음
lst.append(10)
lst # 요론 기본적인 리스트 기능도 가능[1, 1, 1, 2, 2, 3, 10, 10]lst.frequency() # 리스트에서 이것 기능만 추가된거랑 똑같고 나머지는 다 리스트랑 똑같다{1: 3, 2: 2, 3: 1}Appendix: 사용자 정의 자료형의 유용함
- 사용자정의 자료형이 어떤 경우에는 유용할 수 있다.
!pip install matplotlibCollecting matplotlib
Downloading matplotlib-3.5.3-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (11.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 11.2/11.2 MB 97.5 MB/s eta 0:00:00a 0:00:01
Collecting fonttools>=4.22.0
Downloading fonttools-4.38.0-py3-none-any.whl (965 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 965.4/965.4 kB 81.8 MB/s eta 0:00:00
Requirement already satisfied: packaging>=20.0 in /home/koinup4/anaconda3/envs/py37/lib/python3.7/site-packages (from matplotlib) (23.0)
Requirement already satisfied: python-dateutil>=2.7 in /home/koinup4/anaconda3/envs/py37/lib/python3.7/site-packages (from matplotlib) (2.8.2)
Collecting pyparsing>=2.2.1
Downloading pyparsing-3.0.9-py3-none-any.whl (98 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 98.3/98.3 kB 18.6 MB/s eta 0:00:00
Collecting kiwisolver>=1.0.1
Downloading kiwisolver-1.4.4-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 82.9 MB/s eta 0:00:00
Requirement already satisfied: numpy>=1.17 in /home/koinup4/anaconda3/envs/py37/lib/python3.7/site-packages (from matplotlib) (1.21.6)
Collecting cycler>=0.10
Downloading cycler-0.11.0-py3-none-any.whl (6.4 kB)
Requirement already satisfied: pillow>=6.2.0 in /home/koinup4/anaconda3/envs/py37/lib/python3.7/site-packages (from matplotlib) (9.4.0)
Requirement already satisfied: typing-extensions in /home/koinup4/anaconda3/envs/py37/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib) (4.4.0)
Requirement already satisfied: six>=1.5 in /home/koinup4/anaconda3/envs/py37/lib/python3.7/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Installing collected packages: pyparsing, kiwisolver, fonttools, cycler, matplotlib
Successfully installed cycler-0.11.0 fonttools-4.38.0 kiwisolver-1.4.4 matplotlib-3.5.3 pyparsing-3.0.9import pandas as pd
import numpy as np
import matplotlib.pyplot as plt- 예제1
year = ['2016', '2017', '2017', '2017', 2017, 2018, 2018, 2019, 2019]
value = np.random.randn(9)df = pd.DataFrame({'year':year, 'value':value})
df| year | value | |
|---|---|---|
| 0 | 2016 | 0.729447 |
| 1 | 2017 | 0.110630 |
| 2 | 2017 | 0.108119 |
| 3 | 2017 | -0.095107 |
| 4 | 2017 | -0.337716 |
| 5 | 2018 | -0.134635 |
| 6 | 2018 | -2.182677 |
| 7 | 2019 | -0.150227 |
| 8 | 2019 | 0.849774 |
plt.plot(df.year, df.value)TypeError: 'value' must be an instance of str or bytes, not a int
df.year0 2016
1 2017
2 2017
3 2017
4 2017
5 2018
6 2018
7 2019
8 2019
Name: year, dtype: objectdtype이 object 로 되어있어서 그림이 그려지지 않는다.. float로 되어야 할텐데?
에러의 이유: df.year에 str, int가 동시에 있음
np.array(df.year)array(['2016', '2017', '2017', '2017', 2017, 2018, 2018, 2019, 2019],
dtype=object)- 자료형의 형태를 바꿔주면 해결할 수 있다.
np.array(df.year, dtype=np.float64)array([2016., 2017., 2017., 2017., 2017., 2018., 2018., 2019., 2019.])np.array(df.year).astype(np.float64) # 위와 같은 효과array([2016., 2017., 2017., 2017., 2017., 2018., 2018., 2019., 2019.])df.year.astype(np.float64) # 위와 같은 효과0 2016.0
1 2017.0
2 2017.0
3 2017.0
4 2017.0
5 2018.0
6 2018.0
7 2019.0
8 2019.0
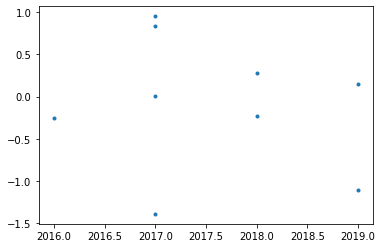
Name: year, dtype: float64plt.plot(df.year.astype(np.float64), df.value,'.')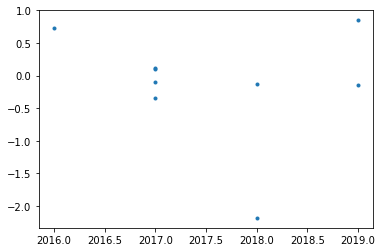
- 예제2
year = ['2016', '2017', '2017', '2017년', 2017, 2018, 2018, 2019, 2019]
value = np.random.randn(9)df = pd.DataFrame({'year':year, 'value':value})
df| year | value | |
|---|---|---|
| 0 | 2016 | -0.254312 |
| 1 | 2017 | 0.839603 |
| 2 | 2017 | -1.386845 |
| 3 | 2017년 | 0.010756 |
| 4 | 2017 | 0.949379 |
| 5 | 2018 | 0.280954 |
| 6 | 2018 | -0.227516 |
| 7 | 2019 | -1.100002 |
| 8 | 2019 | 0.152285 |
np.array(df.year, dtype=np.float64) # "년"이 써있어서 타입을 일괄적으로 바꾸기 어렵다.ValueError: could not convert string to float: '2017년'df.year # 어떤 값이 있는지 확인0 2016
1 2017
2 2017
3 2017년
4 2017
5 2018
6 2018
7 2019
8 2019
Name: year, dtype: objectnp.unique(df.year) # 섞여있는 타입에서는 unique는 동작하지 않는다.TypeError: '<' not supported between instances of 'int' and 'str'L(df.year).frequency(){'2016': 1, '2017': 2, '2017년': 1, 2017: 1, 2018: 2, 2019: 2}- ’2016’과 같은 형태, ’2017년’과 같은 형태, 숫자형이 혼합 .. 이라는 파악 가능 -> 맞춤형 변환이 필요함
'2017년'.replace("년","")'2017'def f(a): # 데이터의 구조를 모르면 이런 함수를 짤 수가 없다. -> 자료의 구조를 확인해준다는 의미에서 freq가 있다면 편리하다.
if type(a) is str:
if "년" in a:
return int(a.replace("년",""))
else:
return int(a)
else:
return a[f(a) for a in df.year][2016, 2017, 2017, 2017, 2017, 2018, 2018, 2019, 2019]df.year = [f(a) for a in df.year]df| year | value | |
|---|---|---|
| 0 | 2016 | -0.254312 |
| 1 | 2017 | 0.839603 |
| 2 | 2017 | -1.386845 |
| 3 | 2017 | 0.010756 |
| 4 | 2017 | 0.949379 |
| 5 | 2018 | 0.280954 |
| 6 | 2018 | -0.227516 |
| 7 | 2019 | -1.100002 |
| 8 | 2019 | 0.152285 |
plt.plot(df.year, df.value, '.')